模型架构:MoE等核心要点
一、MoE架构概述
1.1 什么是MoE
专家混合系统定义:MoE(Mixture of Experts,专家混合系统)是一种特殊的神经网络架构,它将多个"专家网络"(子网络)组合在一起,通过一个"路由器"决定将输入数据发送给哪些专家处理。
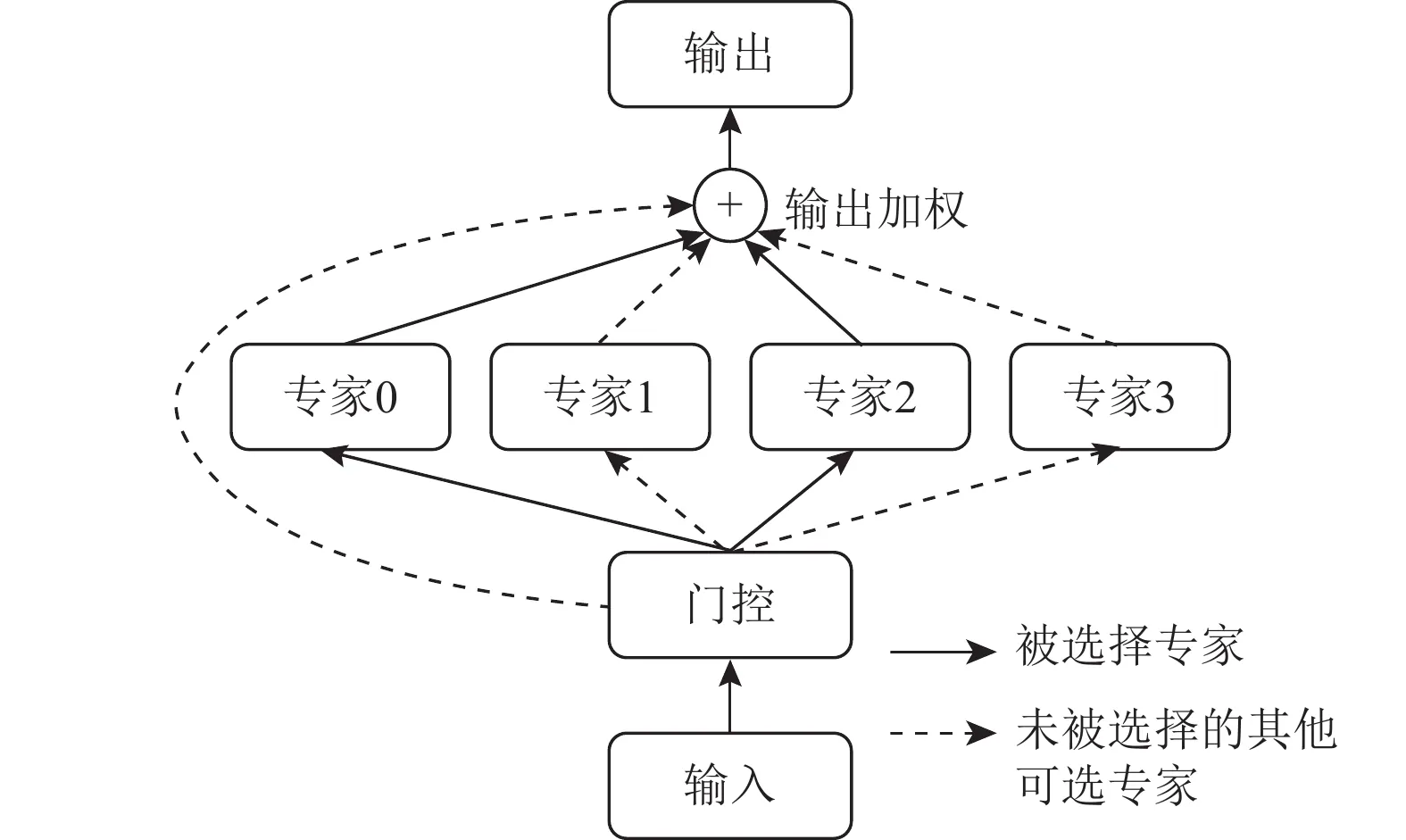
基本原理:想象一个公司有不同部门的专家,每位专家各自擅长解决特定类型的问题。当一个问题出现时,前台接待(路由器)会判断这个问题的性质,然后将它分配给最合适的专家。MoE模型就是这样工作的 - 不同的专家网络处理不同类型的数据,而路由器决定哪些专家应该处理当前输入。
与传统Transformer的区别:传统Transformer模型的每一层都会处理所有输入数据,就像每个问题都要经过公司里的每位员工一样,这会消耗大量资源。而MoE架构则只激活部分网络(专家),大大提高了计算效率。例如,对于一个拥有671B总参数的模型,每次处理可能只需要激活约37B参数(如DeepSeek-V3)。
1.2 MoE的优势
计算效率提升:因为只有部分专家被激活,所以计算量大大减少。这就像一个大型会议,不需要所有人都发言,只需要相关专业的人提供意见即可。在DeepSeek-V2中,与同等性能的密集模型相比,计算资源消耗降低了42.5%。
参数利用率:虽然总参数量很大,但每次处理数据时只使用一小部分,这使得模型可以拥有更大的总体容量,而不会增加推理时的计算负担。以DeepSeek-V3为例,总参数量达671B,但每次处理只激活约5.5%的参数。
专业化能力:不同的专家可以专注于不同类型的任务,如语法分析、逻辑推理、知识检索等,使得模型在处理多样化任务时更加出色。就像一个团队中,有人擅长数学,有人擅长写作,通过分工合作可以处理更复杂的问题。
二、DeepSeek中的MoE实现
2.1 架构设计
专家网络设计:DeepSeek采用了一种称为"细粒度专家"的设计。传统MoE模型中,每个专家是一个完整的神经网络层,而在DeepSeek中,每个专家被进一步细分,使专家数量更多但每个专家规模更小。这就像将团队中的大部门进一步细分为多个小组,每个小组专注于更具体的任务。
路由机制:DeepSeek使用了基于输入内容的动态路由机制,能够根据输入的特征自动选择最合适的专家。例如,当处理代码相关内容时,可能会激活擅长代码理解的专家;而处理数学问题时,则可能激活擅长数学推理的专家。
负载均衡:为了避免某些专家过度使用而其他专家闲置,DeepSeek引入了负载均衡机制。在DeepSeek-V3中,开发了一种无辅助损失的负载均衡策略,通过给每个专家添加动态调整的偏置项来平衡使用率,确保所有专家都能得到适当的训练和使用。
2.2 关键创新
动态路由策略:DeepSeek的路由器不仅考虑当前输入,还考虑序列中前后的上下文信息,使得专家选择更加准确。这就像接待员不仅根据当前问题,还会考虑客户的历史咨询记录来分配最合适的专家。
专家选择机制:DeepSeek使用Top-k选择机制,即对每个输入,选择k个最合适的专家共同处理。这类似于复杂问题需要多个专业领域的专家共同解决,比如一个跨学科的研究项目。
训练优化方法:为了提高训练效率,DeepSeek-V3引入了多令牌预测(MTP)训练目标,模型不仅预测下一个词,还同时预测多个未来的词。这就像不仅预测下一步棋,还能预判后面几步的发展,从而获得更丰富的训练信号。
2.3 性能优化
计算资源利用:通过精细的专家切换和并行计算,DeepSeek模型能够高效利用GPU等硬件资源。在DeepSeek-V2中,最大生成吞吐量提升到原来的5.76倍。
内存管理:采用多头潜在注意力(MLA)技术,将注意力键值缓存压缩成潜在向量,在DeepSeek-V2中,相比于67B参数的密集模型,KV缓存减少了93.3%。对普通用户来说,这意味着在相同的硬件上可以处理更长的文本或对话。
推理加速:通过优化专家调度和计算并行化,大幅提高了模型推理速度。就像一个高效的团队,每个成员都知道自己的任务,并能快速完成,不会有人闲置或等待。
三、其他核心架构要点
3.1 注意力机制优化
高效注意力计算:DeepSeek的多头潜在注意力(MLA)机制通过降维技术大大减少了注意力机制的内存占用。传统注意力机制需要为每个位置存储完整的键值向量,而MLA只需存储一个低维的潜在向量,需要时再恢复成完整向量。
上下文处理:优化的注意力机制使DeepSeek能够处理更长的上下文。DeepSeek-V3支持128K tokens的上下文长度,而通过额外的训练可以扩展到1M tokens。这相当于处理上百页的文档或几个小时的对话而不会"忘记"前面的内容。
长序列支持:通过注意力机制的优化,模型能够更好地捕捉长序列中的远距离依赖关系。例如,能够理解文章开头提到的人物在文章末尾再次出现时的关联,或者在长对话中保持连贯的上下文理解。
3.2 位置编码改进
相对位置编码:与传统的绝对位置编码不同,DeepSeek采用相对位置编码,这使得模型更容易处理可变长度的输入。想象一下阅读一本书,你不需要记住每个词在第几页第几行,而是关注词与词之间的相对位置关系。
旋转位置编码:DeepSeek使用旋转位置编码(RoPE),这种方法通过旋转词向量的维度来编码位置信息,使模型在处理长文本时表现更好。这种编码方式还能更容易地扩展到更长的上下文长度。
位置感知机制:改进的位置编码使模型能够更好地理解词在序列中的位置及其与其他词的关系,从而产生更连贯、更有逻辑的输出。这对于生成长篇文章或进行复杂推理尤为重要。
3.3 激活函数创新
SwiGLU激活:DeepSeek模型采用了SwiGLU(Swish-Gated Linear Unit)激活函数,这种函数结合了Swish和门控机制的优点,可以更好地处理复杂的非线性关系。
门控机制:门控机制允许模型选择性地让信息通过或阻断,类似于智能筛选器,增强了模型处理复杂信息的能力。例如,当处理包含多个概念的长句子时,门控机制可以帮助模型关注最相关的部分。
非线性处理:改进的激活函数使模型能够捕捉更复杂的模式和关系,提高了模型的表达能力。这就像人类思考过程中的"灵光一现",能够建立看似不相关信息之间的连接。
四、训练架构设计
4.1 并行训练策略
数据并行:将训练数据分配给多个GPU,每个GPU使用相同的模型副本处理不同的数据批次,然后汇总梯度。这就像多名教师使用相同的教材教授不同班级的学生,然后分享教学经验。
模型并行:将模型分割到多个GPU上,每个GPU负责模型的一部分。对于DeepSeek这样的大模型尤为重要,因为单个GPU无法容纳完整模型。这类似于大型项目由多个团队共同完成,每个团队负责一个模块。
专家并行:MoE架构的一个关键优势是可以将不同专家分布在不同设备上,实现专家级别的并行。DeepSeek-V3的训练使用了2048个NVIDIA H800 GPU,通过高效的专家并行策略大大加速了训练过程。
4.2 优化器设计
Adam优化器改进:DeepSeek使用改良版的Adam优化器,提高了参数更新的效率和稳定性。这就像一个经验丰富的教练,知道如何根据球员的表现给予恰当的指导,而不是一味地施加相同的训练强度。
学习率调度:采用动态学习率调度策略,在训练不同阶段自动调整学习速率。例如,在初期使用较大学习率快速探索参数空间,后期使用较小学习率精细调整模型参数。
梯度处理:引入了先进的梯度累积和梯度裁剪技术,确保训练过程稳定,避免梯度爆炸或消失的问题。DeepSeek-V3的训练过程非常稳定,整个训练过程中没有出现不可恢复的损失峰值或回滚。
4.3 损失函数设计
主要任务损失:传统的语言模型预训练使用下一个词预测的交叉熵损失,DeepSeek-V3则采用了更先进的多令牌预测目标,同时预测多个未来词汇,提供更丰富的学习信号。
辅助任务损失:为了提高MoE模型的性能,传统方法会添加额外的辅助损失来实现负载均衡。而DeepSeek-V3创新性地引入了无辅助损失的负载均衡策略,通过动态偏置项而非损失函数来调节专家使用率。
正则化策略:采用多种正则化技术,如权重衰减、注意力丢弃等,防止模型过拟合,提高泛化能力。这就像运动员的全面训练,不仅要强化主要技能,还要保持身体各方面的均衡发展。
五、推理架构优化
5.1 推理加速
量化优化:通过参数量化(如FP8混合精度训练),降低模型的内存和计算需求。DeepSeek-V3是首个使用8位训练的大规模语言模型,这就像对高清图片进行压缩,在保持基本视觉效果的同时大大减小文件体积。
注意力优化:多头潜在注意力(MLA)技术不仅节省训练内存,还显著提高了推理效率。在DeepSeek-V2中,KV缓存减少了93.3%,这意味着在相同硬件上可以处理更长的文本输入。
缓存管理:优化的键值缓存管理策略使得模型能够高效处理长上下文对话,无需频繁重新计算先前处理过的信息。这就像人类记忆,我们不需要每次回想时都从头重新构建记忆,而是可以直接访问之前存储的信息。
5.2 内存优化
显存管理:通过高效的参数共享和动态加载,降低模型的显存需求。例如,DeepSeek-V3的MoE架构虽然总参数量高达671B,但推理时只需要激活一小部分,大大减轻了显存压力。
参数共享:DeepSeek模型中,某些专家网络之间共享部分参数,减少总体参数量。这就像不同部门共享某些基础设施,既节约资源又保持功能完整。
动态加载:根据需要动态加载不同专家的参数,而不是一次性加载全部模型。这类似于按需打开应用程序,而不是同时启动电脑上的所有软件,从而节省系统资源。
5.3 部署优化
服务架构:DeepSeek提供多种部署选项,从轻量级到高性能,满足不同场景需求。例如,DeepSeek-MoE 16B可以在单个拥有40GB内存的GPU上部署,无需量化。
负载均衡:在服务器部署中,通过智能请求分发机制,确保系统资源得到充分利用,避免某些节点过载而其他节点闲置。
资源调度:根据任务复杂度动态分配计算资源,确保高效服务。例如,简单的问答可能只需激活少量专家,而复杂的推理任务则可能需要更多专家共同参与。
六、小结
MoE架构作为DeepSeek的核心创新点之一,通过专家混合系统显著提升了模型性能和效率。模型只激活与当前任务相关的专家,而不是使用全部参数,这就像一个高效的组织只调动必要的人员来解决特定问题。结合多头潜在注意力(MLA)、改进的位置编码和先进的训练策略,DeepSeek在训练和推理方面都实现了重大突破,创造了一个既强大又经济高效的语言模型。
通过这些技术创新,DeepSeek模型实现了与密集模型相当甚至更优的性能,同时大幅降低了计算成本和内存需求。这为AI技术的普及和应用拓展提供了重要支持,使更多人能够接触和使用先进的AI技术。
思考问题:
- MoE架构相比传统Transformer有哪些优势和挑战?
- 在实际应用中,如何权衡MoE的计算效率和部署复杂度?